

第一印象与入门体验
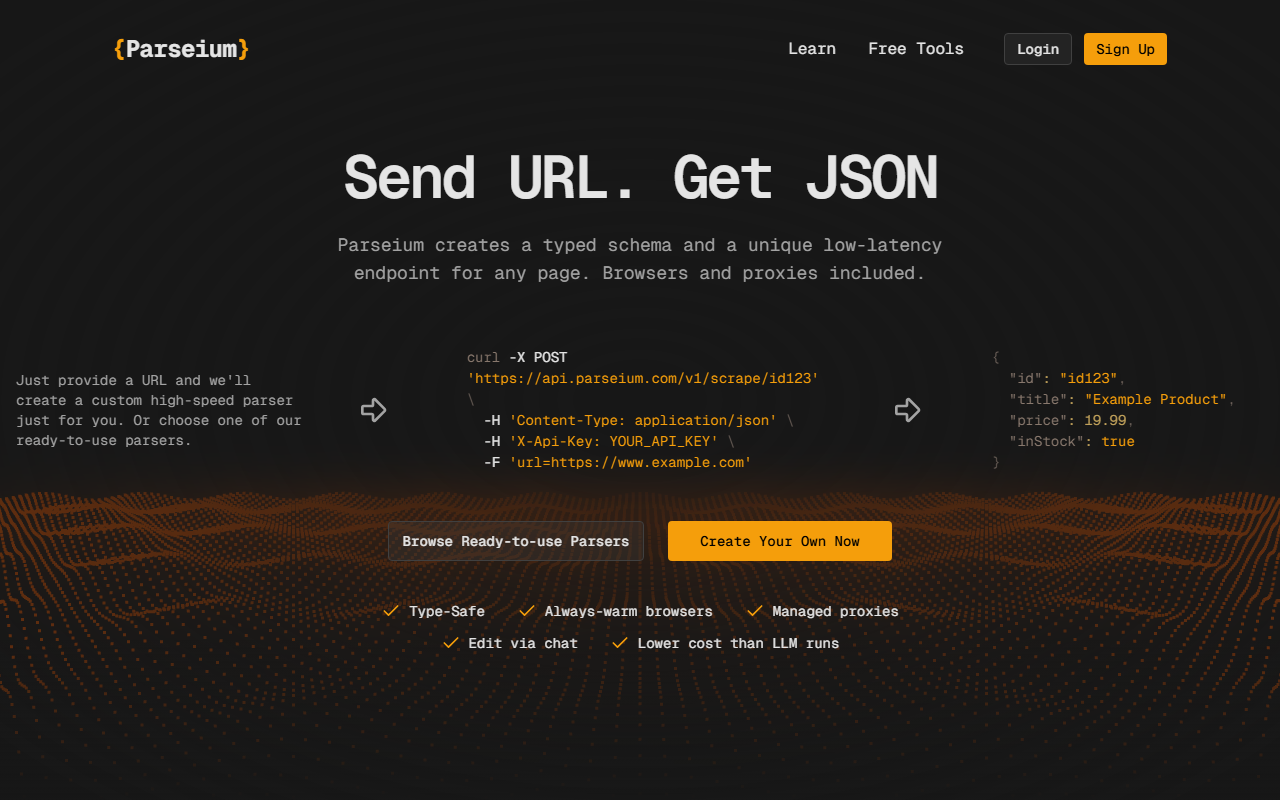
访问Parseium网站后,映入眼帘的是简洁、以开发者为中心的登录页面。标题“Send URL. Get JSON”立即设定了预期。仪表盘需注册后才可见,但主页包含一个实时curl示例和完整的API响应代码片段。我注册测试了免费测试版——无需信用卡。入门指导引导我创建第一个自定义解析器:我将一个URL粘贴到简单输入字段中,几秒钟内Parseium便为该页面生成了一个类型化模式(schema)。界面将模式显示为JSON结构,包含title、price、inStock等字段,并允许稍后通过聊天界面编辑。整个过程不到两分钟。
核心功能与技术深度解析
Parseium解决了一个特定问题:将原始网站HTML转换为干净、类型化的JSON,无需编写解析代码或依赖昂贵的LLM调用。其底层结合了始终预热(always-warm)的无头浏览器、高级旋转代理以及确定性提取逻辑——而非LLM,这确保了低延迟(网站声称大多数页面在10ms内完成解析)。测试免费套餐时,我使用了/parse端点,该端点接受来自任何来源的原始HTML。这意味着你可以使用自己的抓取设置,同时利用Parseium的结构化输出。平台还提供/scrape端点,可一次调用管理整个爬取过程——浏览器、代理和解析。定价在网站上清晰列出:三个层级——Starter($49/月,15万抓取点数,3个自定义API,1 req/s)、Pro($99/月,70万点数,10个API,10个并发抓取器)和Business($299/月,300万点数,30个API,150个并发抓取器)。测试版期间,/parse请求不限量且免费,最高1 req/s。为Instagram、TikTok、Reddit和YouTube提供了预构建抓取器,均返回结构化数据。基于聊天的解析器编辑功能值得注意:你用普通英语描述更改,Parseium自动调整模式或提取逻辑,然后允许你审查并部署新版本。
市场定位与替代方案
Parseium将自己定位为无头浏览器设置、手动XPath/CSS解析以及LLM驱动提取(例如使用GPT-4解析HTML,既慢又不可预测)的替代方案。与Apify的预构建actors市场相比,Parseium提供更低延迟和更简单的“一个URL,一个端点”模型。然而,Apify提供更广泛的即用抓取器和集成生态系统。另一个替代方案是ScrapingBee,它也结合了代理轮换与结构化提取,但ScrapingBee在复杂页面上更依赖AI/LLM提示。Parseium的确定性方法提供了可预测、类型安全的输出——对于无法容忍LLM幻觉的生产管道来说是一个优势。该工具最适合希望以可编程、低维护方式从多个站点提取结构化数据的开发者和数据团队。对于非技术用户或免费套餐中需要高并发(/parse限制为1 req/s)的用户来说不太理想。自我修复功能承诺“即将推出”,这将解决DOM变化破坏解析器这一最大痛点。
优势:确定性输出、低延迟、免费测试版、预热浏览器、基于聊天的编辑、自带HTML选项。局限性:测试版仅3个自定义解析器、免费套餐有速率限制、自我修复尚未上线、无webhook或GUI仪表盘用于监控。总体而言,Parseium是厌倦了脆弱抓取脚本的开发者的一个前景广阔的工具。我建议尝试免费测试版,针对你自己的用例评估其速度和准确性。
访问Parseium官网 https://parseium.com/ 自行探索。













评论