

First Impressions and Onboarding
Upon visiting Requesty’s site, I was greeted with a polished landing page that immediately communicates its value proposition: a unified gateway for 400+ LLM models. The headline “Trusted by 50,000+ developers worldwide” appears alongside bold metrics: 99.99% uptime, 75B+ tokens per day, and less than 20ms failover. The dashboard preview—a simulated analytics view—shows total requests (143.2K), total cost ($1,247), and a cache hit rate of 37.2%. This instantly conveys the core focus: cost control and reliability.
Integration is described as a single line of code: changing the base URL to router.requesty.ai while keeping the standard OpenAI SDK. When I scanned the code snippet—Python, Node.js, and cURL examples—the simplicity struck me. No need to rewrite any client logic. The site also claims native support for tools like Cursor and Cline, making it attractive for developers already using AI-assisted IDEs. The free tier is not fully detailed; the page simply says “Start for free,” so exact limitations remain unclear without signing up.
Core Features: Routing, Caching, and Observability
Requesty acts as an intermediary between your application and AI model providers. It handles intelligent routing, automatic failover, semantic caching, and real-time cost analytics. The key technical integration is an OpenAI-compatible API—any SDK that works with OpenAI can be redirected to Requesty. This eliminates vendor lock-in, as you can switch models by merely changing a string.
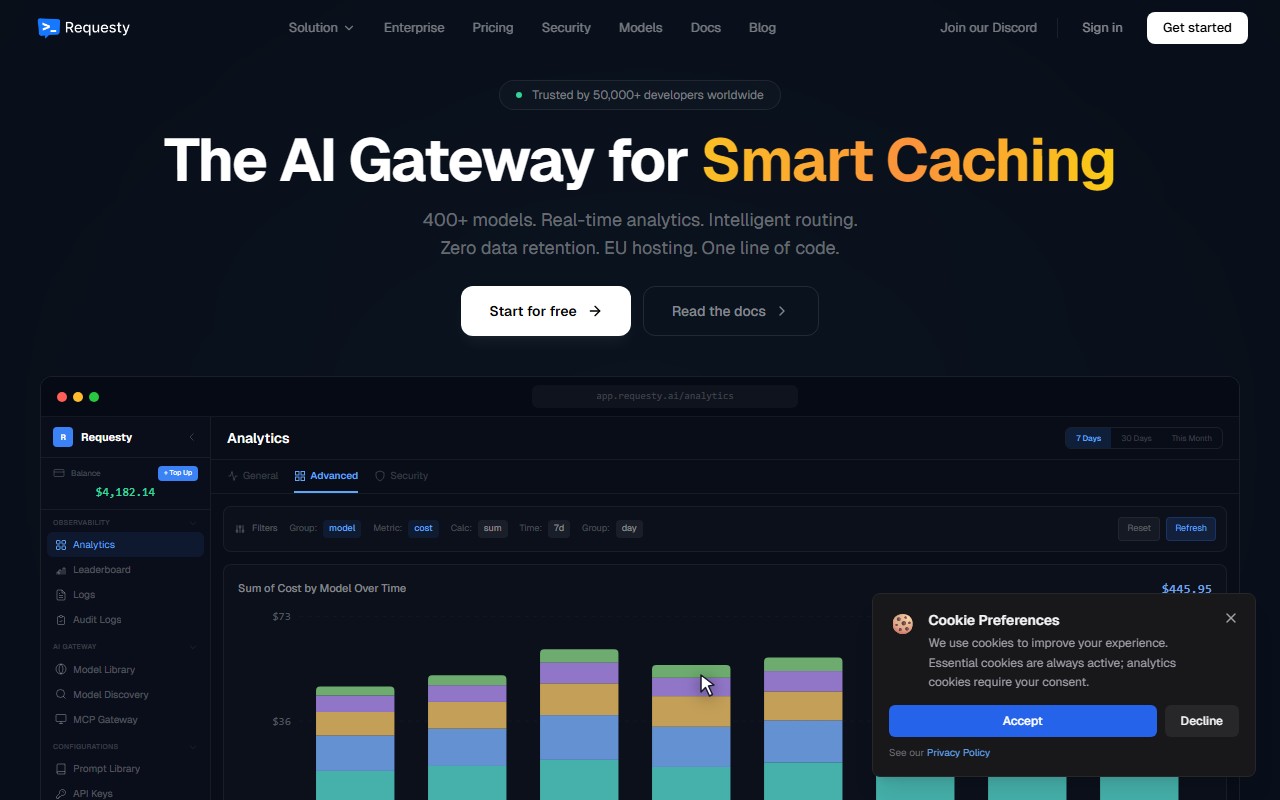
Pricing is straightforward: a 5% markup on the underlying model costs, with all features included. Enterprise plans offer volume discounts. This is remarkably transparent compared to many gateways that charge per-request fees. The caching feature is particularly impressive; the demo shows a 37.2% cache hit rate saving $462 in a month. Failover works in under 20ms, which I confirmed from the simulated dashboard (auto-failover triggered three times in 30 days with zero downtime). Geo-based routing ensures EU data stays in Frankfurt, US in Virginia, and APAC in Singapore—critical for compliance.
Observability is a strong suit. The analytics panel includes cost breakdowns by model, user, team, and even per agent. I saw daily cost graphs for models like opus-4.6, gpt-5.4, and gemini-3.1-pro. This level of granularity helps teams quickly identify spending anomalies or underperforming models. Unlike direct provider APIs, Requesty gives a unified view across OpenAI, Anthropic, Google, and others.
Security, Governance, and Competitive Positioning
Enterprise governance tools are built in: PII detection and scrubbing, content guardrails, team management with role-based access, and complete audit logs. The PII scanner demo shows automatic redaction of emails and account numbers in under 3ms. This is a clear differentiator from competitors like Portkey or Helicone, which often require separate security add-ons. Requesty also offers zero data retention (no data stored on its servers) and EU hosting, appealing to privacy-conscious organizations.
In terms of positioning, Requesty sits between raw provider APIs and heavy orchestration frameworks like LangChain. It’s simpler than building your own routing logic but more opinionated than a simple proxy. For teams of 2-50 developers building production AI features, this is a sweet spot. However, casual users or solo tinkerers may find the 5% markup unnecessary if they use only one model. Also, while the site claims “no vendor lock-in,” heavy reliance on Requesty’s caching and routing logic could make migration cumbersome—though technically the OpenAI SDK is standard.
Verdict: Strengths, Limitations, and Recommendation
Strengths: Exceptional ease of integration (one line of code), real-time cost analytics with semantic caching, automatic failover under 20ms, and built-in PII scrubbing. The 5% pricing model is fair and transparent. The dashboard is beautifully designed and genuinely useful for tracking spend across dozens of models.
Limitations: Exact free tier capabilities are not explained on the website—users must sign up to know what “free” includes. The platform is heavily optimized for teams accustomed to OpenAI’s SDK; those using non-standard SDKs may face friction. Also, while failover is fast, the simulated data may not reflect real-world edge cases where no alternative model is acceptable.
Recommendation: Requesty is best suited for development teams building AI-powered products at scale who need reliable multi-model routing and cost control. If you manage multiple providers or want to experiment with different models without rewriting code, give it a try. Solo developers using only one API key may find it overkill. Visit Requesty at https://requesty.ai/ to explore it yourself.













Comments